DiscreteRTC: Discrete Diffusion Policies are Natural Asynchronous Executors
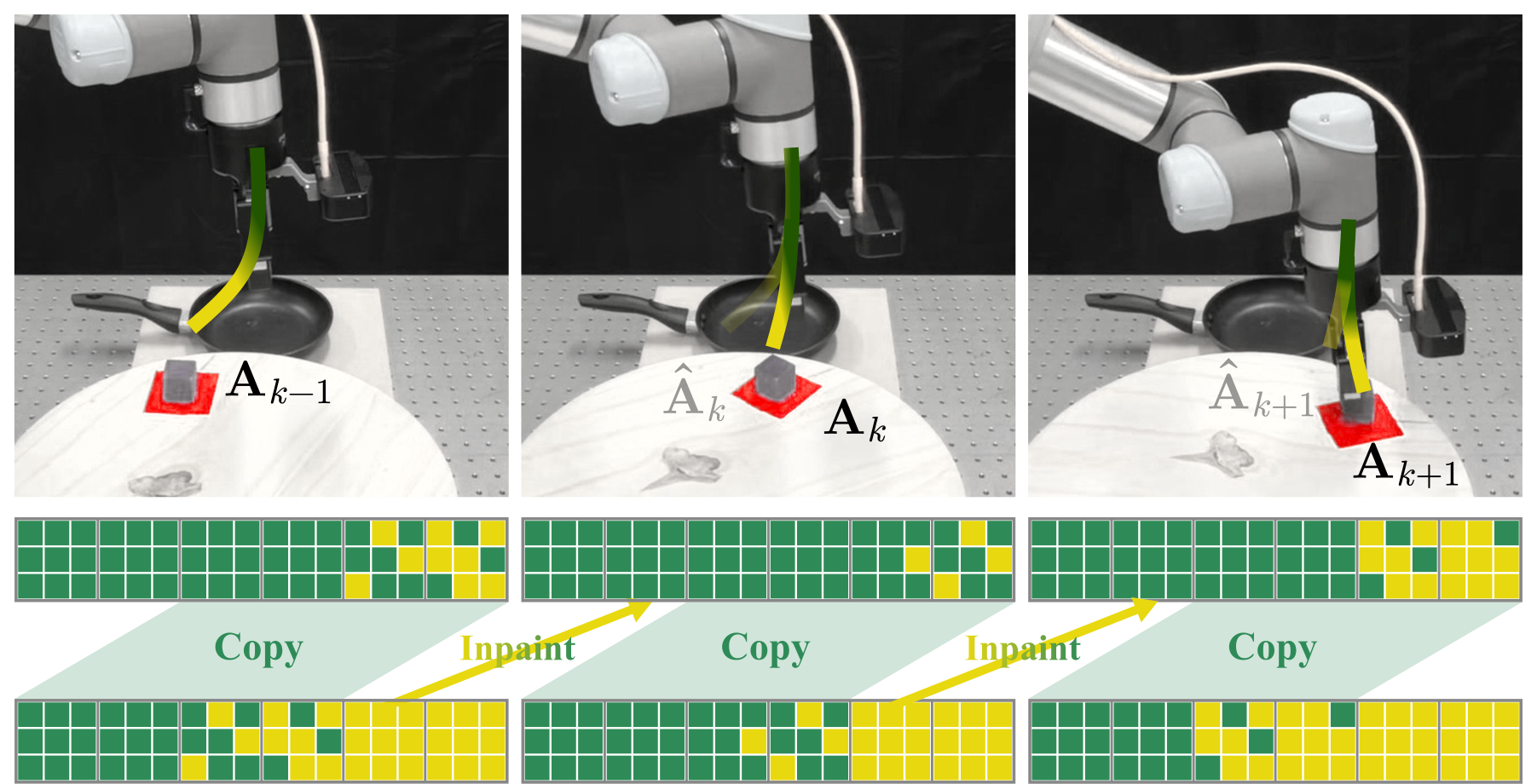
Figure 1: Async Execution with discrete diffusion policies solving dynamic manipulation. Gray rectangles and blocks represent the action chunks and the actions. Yellow and green cubes represent the masked and unmasked action tokens. During each inference cycle, discrete diffusion policies copy the tail of the last action chunk as the committed prefix, and inpaint upon it by simply forwarding itself. Compared with flow-matching-based inpainting that relies on $\Pi$GDM, discrete-diffusion-based inpainting inference is simpler to implement, faster at inference, and better at execution.
TL;DR
Flow-matching-based real-time chunking (RTC) is ill-suited for asynchronous execution due to four critical limitations. By replacing the action head with a discrete diffusion policy, all the aforementioned limitations can be resolved at once. Or, to put it simply: Discrete diffusion policies are natural asynchronous executors. During asynchronous execution, discrete diffusion policy achieves:
Abstract
Unlike chatbots, physical AI must act while the world keeps evolving. The inter-chunk pause of synchronous executors is fatal for dynamic tasks — regardless of how fast the inference is. Asynchronous execution — thinking while acting — is therefore a structural requirement, and real-time chunking (RTC) makes it viable by recasting chunk transitions as inpainting: freezing committed actions and consistently generating the rest.
However, RTC with a flow-matching policy is structurally suboptimal: its inpainting comes from inference-time corrections rather than the base policy, yielding little pre-training benefit, specific fine-tuning, heuristic guidance weights, and extra computation that inflates the latency.
In this work, we observe that discrete diffusion policies, which generate actions by iteratively unmasking, are natural asynchronous executors that resolve all limitations at once: they are fine-tuning free since inpainting is their native operation, while early stopping further provides adaptive guidance and reduces inference cost.
We propose DiscreteRTC, which replaces external corrections with native unmasking, and show on dynamic simulated benchmarks and real-world dynamic manipulation tasks that it achieves higher success rates than continuous RTC and other baselines — while being simpler to implement, faster at inference, and better at execution.
Flow-Matching is Not Suitable for RTC
RTC was specifically designed for flow-matching policies — the predominant action head in today's state-of-the-art VLAs. Yet, as we systematically show, RTC with a flow-matching head is far from ideal with four critical limitations, all stemming from the same root cause: the inpainting capability comes from inference-time correction (e.g., $\Pi$GDM), not from the base policy.
Four Critical Limitations
Figure 2: RTC with a flow-matching head. Color encodes noise level (green = clean, yellow = pure noise).
Inpainting with Flow-matching
Flow-matching pre-training corrupts every action in a chunk at a single, consistent noise level $\tau$. RTC inference instead starts from an inconsistent chunk — 0 for committed, 1 for new, interpolated in between — a pattern the model has never seen. Therefore, $\Pi$GDM corrections are inevitable and scaling pre-training does not directly improve asynchronous performance.
Adequate inpainting quality demands a dedicated fine-tuning stage with techniques such as action-suffix conditioning to explicitly introduce the inpainting-specific noise pattern. This adds training complexity, risks interfering with base generation quality, and is especially burdensome for large VLAs already expensive to fine-tune.
$\Pi$GDM's soft-masking weights $\mathbf{W}$ follow a hand-crafted exponential-decay schedule, and the clipping threshold $\beta$ is fixed across delays, execution horizons, and tasks — validated only empirically. The schedule cannot adapt to inference-time conditions.
Computing the guidance term at every denoising step requires a vector-Jacobian product (VJP), which roughly doubles per-step computation — ironically inflating the very latency RTC was designed to hide.
Discrete Diffusion Policies are Natural Asynchronous Executors
Rather than seeking innovation within the flow-matching paradigm, our key observation is structural: replacing the action head with a discrete diffusion policy resolves all four limitations at once. In discrete diffusion, inpainting is the native operation — given a partially masked token sequence, the policy reconstructs the target chunk by predicting the masked tokens, identical to standard masked generation.
All Resolved at Once
Figure 3: RTC with a discrete diffusion head. Color encodes masking status (green = unmasked, yellow = masked).
Inpainting with Discrete Diffusion
Discrete diffusion policies are pre-trained to inpaint upon randomly masked sequences — structurally identical to RTC's inference-time pattern. Scaling pre-training (model, data, compute) directly improves asynchronous performance, and the native forward pass suits inference-time inpainting out of the box.
Inpainting-specific patterns are implicitly introduced during pre-training, making discrete diffusion a fine-tuning-free approach for high-quality, out-of-the-box asynchronous execution — no extra loss term, training stage, or implementation work.
Once a token is unmasked, it already carries a clear action semantic — unlike flow-matching, where the chunk is only valid at $\tau{=}1$. We can early-exit inference once the next $s$ actions after the $d$ committed ones are unmasked; the remaining $H-d-s$ partially-unmasked tokens carry over as a natural and adaptive guidance signal for the next inference, replacing the heuristic fixed schedule.
With committed tokens from previous chunks, the tokens to unmask per inference shrink to roughly $s/H$ of the original (or at least $1-d/H$). DiscreteRTC reduces inference cost rather than inflating it — or, alternatively, keeps the step budget fixed and produces finer-grained actions at the same compute as from-scratch generation.
Experiments
5.1 Simulated Benchmark: Kinetix
We evaluate DiscreteRTC on Kinetix — a dynamic-task benchmark where added Gaussian actuation noise makes closed-loop corrections critical. Built on the official RTC codebase, the flow-matching and discrete diffusion policies share the same architecture (only the final logits layer differs) and use a trivial $512$-bin action quantization; each datapoint averages 2,048 trials.
Baselines (same architecture, different async strategies)
- Naive Async — chunks regenerated from scratch, switched when ready.
- BID — rejection sampling for cross-chunk continuity ($N{=}16$, no weak policy).
- RTC — flow-matching with $\Pi$GDM inpainting + soft masking (continuous-policy SOTA).
Three additional variants are introduced under Extended Results below (Training-time Continuous RTC, DiscreteRTC + Fixed Steps, DiscreteVLASH).
Across delays, DiscreteRTC consistently beats ContinuousRTC and other variants on both solve rate and throughput. Three further takeaways from the extended results: (1) DiscreteRTC outperforms Training-time Continuous RTC despite being fine-tuning free; (2) at the same compute, DiscreteRTC + Fixed Steps lifts performance via finer-grained actions; (3) DiscreteVLASH stabilizes performance across delays at a small low-delay cost — DiscreteRTC composes cleanly with advanced inference-time methods.
5.2 Real-World Results
We validate DiscreteRTC on a UR5e + Robotiq gripper with a wrist-mounted RGB camera on a single RTX 4090. All policies share a Qwen2.5-VL-3B-Instruct VLM backbone with a layerwise cross-attention DiT action head (StarVLA). Three reactiveness-stress tasks — Dynamic Pick (moving object), Dynamic Place (moving platform), and Hockey Defend (defending a high-speed puck) — are each evaluated over 20 trials. Pick & Place run closed-loop at 20 Hz, while Hockey Defend runs at 50 Hz with 2× linear interpolation to a 100 Hz servo stream to meet its far tighter reactiveness budget.
Air Hockey Defend
Hockey Defend is the most demanding stress test: the robot must block a high-speed puck launched by an opponent policy, which requires both fast inference and the smooth, uninterrupted execution that only asynchronous control provides. Here the synchronous baselines and flow-matching ContinuousRTC completely fail (0%) — the inter-chunk pause and $\Pi$GDM overhead are fatal at this speed. Even against training-time ContinuousRTC, which pays an extra fine-tuning cost, the fine-tuning-free DiscreteRTC still wins by a large margin (65% vs. 35%), empirically reaffirming that discrete diffusion policies are natural asynchronous executors.

Figure 6: Real-world setup for Dynamic Pick & Dynamic Place — UR5e + Robotiq gripper, wrist-mounted RGB, turntable target.

Figure 7: Air Hockey Defend setup — the robot must defend a high-speed puck launched by an opponent policy, demanding both efficient inference and smooth asynchronous execution.
Figure 8: Real-world results across the three dynamic tasks (success rate over 20 trials per task and average inference time on a single RTX 4090). Both Sync baselines completely fail (0%), confirming reactive asynchronous execution is indispensable. DiscreteRTC tops ContinuousRTC with the largest gaps on the continuously moving Dynamic Pick and the high-speed Hockey Defend. Costs move in opposite directions: ContinuousRTC inflates flow-matching inference ($\sim$1.7× $\Pi$GDM overhead), while DiscreteRTC reduces discrete diffusion inference — RTC and discrete diffusion compound rather than conflict.
Dynamic Pick
Dynamic Place
Hockey Defend
Discussion & Future Steps
Conclusions
We presented DiscreteRTC, which exploits the native inpainting capability of discrete diffusion for asynchronous real-time control — eliminating the need for inpainting-specific fine-tuning, heuristic guidance weights, and extra inference cost inherent to flow-matching-based RTC. Simulated and real-world experiments show that DiscreteRTC outperforms ContinuousRTC and other asynchronous baselines, while being simpler to implement, faster at inference, and better at execution — and composes seamlessly with methods such as VLASH for further gains.
Limitations
Each limitation coincides with an active research direction whose progress directly benefits DiscreteRTC:
- Naive $k$-bin quantization ignores temporal structure and yields overly long token sequences, motivating compact, temporally aware tokenizers.
- Our modularized AR-VLM + discrete diffusion head prevents the backbone from participating in iterative unmasking — a gap unified discrete-diffusion VLAs aim to close.
- Traditional max-confidence unmasking does not yet translate the natural schedule into consistent gains.
Future Steps
- A time-causally ordered action tokenizer producing temporally ordered, compact token representations.
- A unified discrete diffusion VLA in which observation reasoning and action generation share the same backbone.
- An appropriate yet principled unmasking strategy — emerging techniques such as AR-block decoding align better with the implicit autoregressive structure induced by RTC.
Citation
@article{wang2026discreterc,
title = {DiscreteRTC: Discrete Diffusion Policies are Natural Asynchronous Executors},
author = {Wang, Pengcheng and Hong, Kaiwen and Peng, Chensheng and
Driggs-Campbell, Katherine and Tomizuka, Masayoshi and
Xu, Chenfeng and Tang, Chen},
journal = {arXiv preprint},
year = {2026}
}